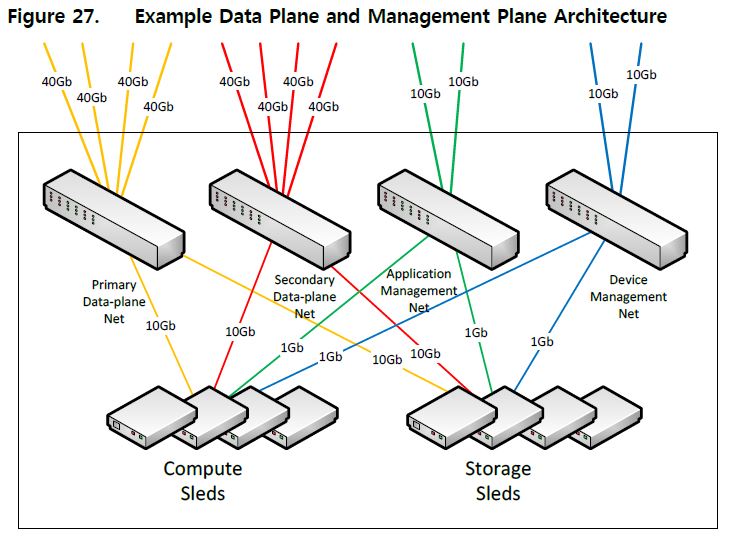
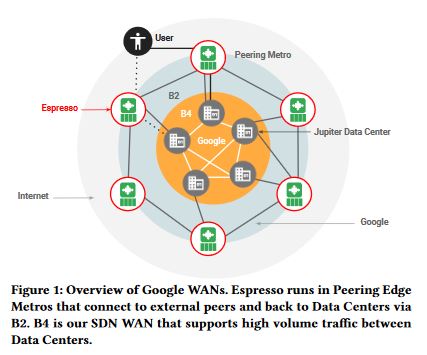
This post seeks to distinguish between the multiple aspects and phases of networking projects. Network Architecture and Network Design are the phases of a networking project carried out first. Then comes the Project Implementation phase along with configurations by Network Engineers.
Some experts have included an Analysis phase as part of, or before, the Network Architecture phase. The concepts being that first an analysis needs to be done on the flows expected from the new network.
Before Network Architecture the Analysis phase consists of gathering the User Requirements, Application Requirements, Application Types, Performance Requirements, Bandwidth Requirements, Delay Requirements etc. After gathering these requirements a Customer Requirements Document (CRD) can be made consisting of all the expectations and requirements from the network. This document will assist with project management throughout the network life cycle and for sufficiently large projects its a good exercise.
Once the requirements are gathered a Flow Analysis can be done to identify the flows required from the network. Data Source and Data Sinks, Critical Flows and per Application flows etc. are analyzed as part of Flow Analysis exercise.
Once the requirements are known and flows are known this can lead to decisions regarding the Network Architecture. The Network Architecture term is generally used with the Network Design term as one but according to one definition it is distinguished from Network Design such that the Architecture consists of the technological architecture while the design consists of specific networking devices selected and vendors selected for the architecture to be implemented on ground. This means, for example, that the Network Architecture will deal with whether to use OSPF or ISIS and how to use them and the Network Design will cover which specific vendor router to use. They are closely linked.
Once the flows are known it can be discussed what the architecture can be. This will consist of primarily deciding the protocols, the addressing and the routing architecture which can be used to facilitate the required flows. Once it is decided which network technologies to use for the flows (such as OSPF, ISIS, MPLS, L2VPN, L3VPN, IPSec, BGP, Public Internet, VXLAN, EVPN, Ethernet etc) a diagram can be made of the architecture. Multiple iterations and permutation of the various architectures will come forward from the discussions over what the architecture could be to facilitate all the flows and provide a resilient network. For each of the protocols listed above, and any other to be used, the clogs available in each can be discussed in detail. It can be discussed and decided regarding how the combinations of multiple protocols will be used to meet all the flows and meet the requirements from the network. If there are cloud connectivity requirements it will be discussed how (which protocol) and where to connect to the cloud. Once an architecture is decided and protocols are selected and the tools within the protocols which are to be used are listed then they can be summed up in a document and in diagrams.
After this phase comes the Design decisions phase. This is close to the architecture phase but this is where the vendor of that OSPF router is selected. This is where the specific router is selected from the multiple router offerings available from the selected vendor. Device vendor selection and specific device selection is a task of its own and is a separate effort in networking projects.
Also as part of the Design it will also be decided which Service Provider to use for Internet and WAN links. It will be decided which service offering will be used from the SP Vendor. If the application and system contain Public Cloud use (including Hybrid On-Prem) than it will be decided which specific connectivity mechanism and location the cloud will connect to. Will it be IPSec over Internet or over Direct Connect and where and how. Will it be the biggest MPLS VPN provider on the market or the smaller one. Will it be the biggest BGP Internet Transit provider or the smaller one.
Once the requirements are known; Once the flows are knows ; Once protocols and architecture is known ; Once the device vendors and device type and SP offerings are known and once all of these are selected than comes the implementation phase.
Engineering is a broad term which can encompass all of the above and more but as things stand here we can say that a Network Engineer as part of the engineering phase will configure and deploy the devices, configure and deploy the WAN links, configure and deploy the Internet links, configure and deploy the cloud connectivity VPNs and configure and deploy the interconnections in the network. This network engineering implementation effort is after the Requirements/Flows/Arch/Design phase as its an effort on ground and on site to implement the network and make things run. Up until this phase all the previous phases were on paper and this one is on ground practical work.
The previous Requirements/Flow/Protocols Architecture/Design and even initial aspects of the engineering phase can be done in office in meeting rooms. Initial aspects of engineering phase consisting of configurations and parameters to be used can be also decided before going out in the field. Once on ground and on site implementation starts than this is an effort of its own and can be considered as Project Deployment and Project Implementation. It entails device delivery, WAN link delivery, device power on, WAN link testing, Internet Link testing, Cloud VPN delivery, configurations and testing etc. This is a phase of its own and is an effort which is more akin to technical project management as well as it is more of an on ground project coordination and project management effort too. This is because of its physical, geographical and on site implementation aspects.
Depending on the type of project the implementation phase can consist of outage windows and maintenance windows and a lot of coordination to implement the new devices and new links.
Hence we can say that a networking project consists of separate requirements gathering, flows analysis, architecture, design and implementation phases. This means that a networking project can be divided into smaller multiple projects each consisting of these above phases. Each phase also requires a skill of its own. For example the Requirements, Flow Analysis, Architecture and Design phases are generally handled by Network Architects, Solution Architects and Network Design Engineers. The configuration and deployments aspect is handled more by Network Engineers and the Project implementation and coordination efforts are handled by Project Managers.
Multiple and simultaneously such large scale projects having all these phases going on at various levels would be run under a Program given the size of the organization is sufficiently large and that there are multiple streams of such projects being carried out.
I hope you enjoyed the good read.
Happy networking.
Habib